JOINs and Denormalization
Since Postgres is a relational database, its data model is heavily normalized, often involving hundreds of tables. In ClickHouse, denormalization can be beneficial at times to optimize JOIN performance. This page covers common JOINs tips and best practices to denormalize data.
Optimizing JOINs
For most use cases, running queries with JOINs (as in Postgres) on raw data in ClickHouse should perform significantly better than in Postgres.
You can run the JOIN queries without any changes and observe how ClickHouse performs.
If case you want to optimize further, here are a few techniques you can try:
- Use subqueries or CTE for filtering: Modify JOINs as subqueries where you filter tables within the subquery before passing them to the planner. This is usually unnecessary, but it's sometimes worth trying. Below is an example of a JOIN query using a sub-query.
-
Optimize Ordering Keys: Consider including JOIN columns in the
Ordering Keyof the table. For more details, refer to the page on Ordering Key. -
Use Dictionaries for dimension tables: Consider creating a dictionary from a table in ClickHouse to improve lookup performance during query execution. This documentation provides an example of how to use dictionaries to optimize JOIN queries with a StackOverflow dataset.
-
JOIN algorithms: ClickHouse offers various algorithms for joining tables, and selecting the right one depends on the specific use case. Below are two examples of JOIN queries using different algorithms tailored to distinct scenarios: in the first case, the goal is to reduce memory usage, so the partial_merge algorithm is used, while in the second case, the focus is on performance, and the parallel_hash algorithm is used. Note the difference in memory used.
Denormalization
Another approach users follow to speed up queries is denormalizing data in ClickHouse to create a more flattened table. You could do this with Refreshable Materialized views or Incremental Materialized views.
Two main strategies will be explored when denormalizing data using materialized views. One is to flatten the raw data with no transformation simply; we'll refer to it as raw denormalization. The other approach is to aggregate the data as we denormalize it and store it in a Materialized view; we'll refer to it as aggregated denormalization.
Raw denormalization with Refreshable Materialized Views
Using Refreshable Materialized views to flatten data is easy and allows for the filtering out of duplicates at refresh time, as described in the deduplication strategy page.
Let's take an example of how we can achieve that by flattening the table posts and users.
After a few seconds the materialized view is populated with the result of the JOIN query. We can query it with no JOINs or FINAL keyword.
Aggregated denormalization with Refreshable Materialized Views
It is also a common strategy to aggregate the data and store the result in separate tables using Refreshable Materialized Views for even faster access to results but at the cost of query flexibility.
Consider a query that joins the table posts, users, comments, and votes to retrieve the number of posts, votes, and comments for the most upvoted users. We will use a Refreshable Materialized View to keep the result of this query.
The query might take a few minutes to run. In this case, there is no need to use a Common Table Expression, as we want to process the entire dataset.
To return the same result as the JOIN query, we run a simple query on the materialized view.
Raw denormalization using Incremental Materialized View
Incremental Materialized Views can also be used for raw denormalization, offering two key advantages over Refreshable Materialized Views (RMVs):
- The query runs only on newly inserted rows rather than scanning the entire source table, making it a suitable choice for massive datasets, including those in the petabyte range.
- The materialized view is updated in real-time as new rows are inserted into the source table, whereas RMVs refresh periodically.
However, a limitation is that deduplication cannot occur at insert time. Queries on the destination table still require the FINAL keyword to handle duplicates.
When querying the view, we must include the FINAL modifier to deduplicate the data.
Aggregated denormalization using Incremental Materialized View
Incremental Materialized View can also aggregate data as it gets synchronized from PostgreSQL. However, this is a bit more complex as we must account for duplicates and deleted rows when aggregating them. ClickHouse supports a specific table engine, AggregatingMergeTree, that is specifically designed to handle this advanced use case.
Let's walk through an example to understand better how to implement this. Consider a query that calculates the number of new questions on StackOverflow per day.
One challenge is that each update in PostgreSQL creates a new row in ClickHouse. Simply aggregating the incoming data and storing the result in the destination table would lead to duplicate counts.
Let’s look at what’s happening in ClickHouse when using a Materialized view with Postgres CDC.
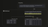
When the row with id=6440 is updated in PostgreSQL, a new version is inserted into ClickHouse as a separate row. Since the Materialized View processes only the newly inserted block of rows and does not have access to the entire table at ingest time, this leads to a duplicated count.
The AggregatingMergeTree mitigates this issue by allowing the retention of only one row per primary key (or order by key) alongside the aggregated and state of the values.
Let's create a table daily_posts_activity to store the data. The table uses AggregatingMergeTree for the table engine and uses AggregateFunction field type for the columns Questions and Answers.
Next, we ingest data from the posts table. We use the uniqState function to track the field's unique states, enabling us to eliminate duplicates.
Then, we can create the Materialized view to keep running the query on each new incoming block of rows.
To query the daily_posts_activity, we have to use the function uniqMerge to combine the states and return the correct count.
This works great for our use case.
The deleted rows in PostgreSQL will not be reflected in the daily_posts_activity aggregated table, which means that this table reports the total number of posts ever created per day but not the latest state.